CDU-Wähler mögen Fußball und deutsche Marken, FDP-Anhänger sind gegen Tempolimits und schätzen teure Sportmode, Parteineutrale und Wechselwähler interessieren sich für Haustiere – das ergeben jedenfalls laut einer aktuellen Studie Datenanalysen von Facebook- und Twitter-Profilen. Die sozialen Netzwerke bieten wahre „Datenschätze“ für Parteien im Wahlkampf. Aus öffentlich zugänglichen Angaben der Nutzer lassen sich, wenn man es möchte, durch Big Data maßgeschneiderte Kampagnen für verschiedene Zielgruppen ableiten. Auch die Frage, wo es Gemeinsamkeiten zwischen der eigenen Wählerschaft und möglichen Koalitionspartnern gibt, ließe sich beantworten.
Spätestens seit der US-Statistiker und Wahlforscher Nate Silver bei den US-Präsidentschaftswahlen im Herbst 2012 die Gewinner sämtlicher 50 Bundesstaaten anhand solcher Datenanalysen korrekt voraussagte, fasziniert das Thema Big Data Markt- und Meinungsforscher in aller Welt. Auch im Vorfeld der deutschen Bundestagswahl 2013 beschäftigten sich zahlreiche Wissenschaftler und IT-Dienstleister mit der Analyse großer Datenmassen aus dem Netz und veröffentlichen Prognosen auf Seiten wie Twitterbarometer oder Fanpage Radar. Innovative, äußerst leistungsfähige Analysetools, so das Kalkül, könnten verborgene Zusammenhänge aufzeigen, wenn sie nur ausreichend große Datenmengen schnell genug und vollautomatisch durchforsten.
Was für Wahlkämpfer oder Marketingtreibende verlockend klingt, hat für Datenschützer allerdings auch eine dunkle Seite: Im Sommer 2013 wurde bekannt, dass der US-Nachrichtendienst NSA das Überwachungsprogramm „Prism“ schon länger gezielt dazu einsetzt, den weltweiten Datenverkehr abzuhören und mit Big Data-Tools automatisch auf sicherheitsrelevante Zusammenhänge zu analysieren.
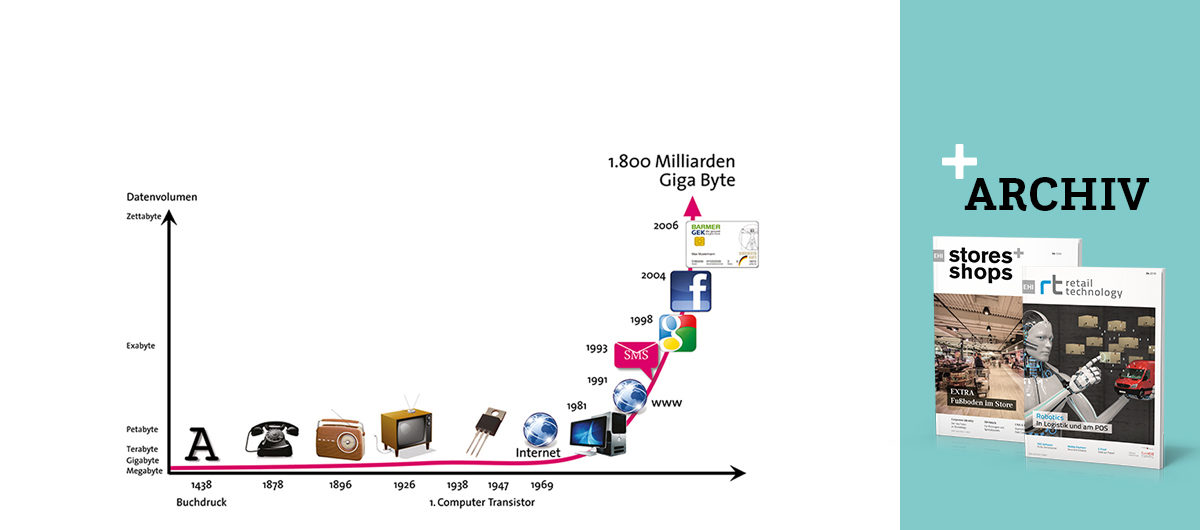
Obwohl sich die Kapazitäten zur Datenverarbeitung weltweit etwa alle 18 Monate verdoppeln, können Hard- und Software kaum noch mit der Datenflut Schritt halten. Die NSA baut beispielsweise in Bluffdale im US-Bundesstaat Utah derzeit ein neues Rechenzentrum, das US-Medien zufolge bis zu 150.000 qm Serverraum umfassen soll. Doch nicht nur E-Mails, sondern vor allem auch Technologien wie RFID, Ambient Intelligence, Smartphones sowie die immer stärkere Akzeptanz und Nutzung von Social-Media-Anwendungen lassen das Datenaufkommen explodieren, so der Branchenverband Bitkom. Bis zum Jahr 2020 könne die Datenmenge auf gigantische 40 Zettabyte anwachsen, prognostiziert das Markforschungsunternehmen IDC in der aktuellen Studie „Digital Universe“ im Auftrag des IT-Unternehmens EMC.
Drastisch gesunkene Hardware-Preise
Ähnlich wie im Weltall, wo Forscher gerade erst mit der Erkundung des nächstgelegenen Planeten begonnen haben, wird auch im digitalen Universum bisher nur ein verschwindend geringer Bruchteil der erzeugten Daten analysiert und als unternehmerische Entscheidungsgrundlage genutzt. Während es jedoch im Raketenbau und in der bemannten Raumfahrt seit den 60er-Jahren keine bahnbrechenden Technologiesprünge gab, entwickelt sich die Datenverarbeitung rasant weiter.
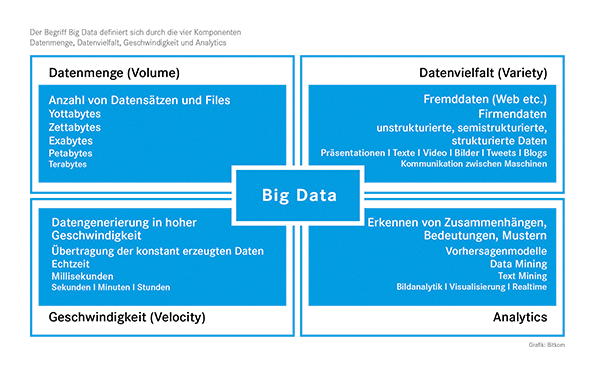
Der Begriff Big Data definiert sich durch die vier Komponenten Datenmenge, Datenvielfalt, Geschwindigkeit und Analytics. (Grafik: Bitkom)
„Moderne Storage-Systeme und Prozessoren erlauben heute eine schnelle, hoch skalierbare und intelligente Datenverwaltung bei drastisch gesunkenen Hardware-Preisen“, sagt Carsten Bange, Geschäftsführer des Business Application Research Centers BARC in Würzburg. Das unabhängige Forschungs- und Beratungsinstitut für Unternehmenssoftware beschäftigt sich schwerpunktmäßig mit BI- und ERP-Lösungen. Kostete ein Gigabyte Speicher Anfang 2000 noch 16 Dollar, sind es heute laut BARC nur noch 6 Cent. Auch auf der Software-Seite können Anwender aus einer stetig steigenden Zahl von Technologien und Services zur Datenanalyse in unterschiedlichen Investitionsklassen wählen – angefangen von Standard-BI-Werkzeugen und Standard-Datenbanken bis zur flexibel abrechenbaren Big Data-App aus der Cloud.
Für Unternehmen ergeben sich aus den verbesserten Speicher- und Analysemöglichkeiten große Chancen, aber zugleich auch neue Herausforderungen. Wer das Trend-Thema Big Data ignoriert, riskiert Wettbewerbsnachteile. „Es gibt keinen Grund, sich nicht ernsthaft die Frage zu stellen, was man mit den eigenen Daten anfangen kann“, mahnt Carlo Velten von der IT-Beratung Experton Group. Und auch Carsten Bange vom BARC ist überzeugt, dass auf Dauer nur solche Unternehmen erfolgreich sein werden, denen es gelingt, die Schätze zu heben, die sich in den eigenen Datenbergen verstecken.
Insbesondere im Controlling sowie in den Bereichen Marketing und Vertrieb erhoffen sich Unternehmen wertvolle Erkenntnisse durch Big Data, zeigt eine aktuelle Umfrage des BARC unter rd. 270 europäischen IT – und Fachbereichsmanagern, u.a. auch aus dem Groß- und Einzelhandel. Zu den häufig genannten Zielen von Big Data-Projekten zählen danach zum Beispiel bessere strategische Entscheidungen, verbesserter Kundenservice, zielgerichtetere Marketingaktionen, geringere Kosten und bessere Kundenbindung.
Neue Erkenntnisse für die Fachabteilungen ergeben sich dabei nach einhelliger Ansicht von Experten nicht allein aus der zunehmenden Masse ausgewerteter Daten, sondern vor allem aus der Analyse polystrukturierter Datenquellen. Neben strukturierten Daten, beispielsweise Umsatz- und Kennzahlen, gilt es im Rahmen von Big Data auch teilstrukturierte oder komplexe unstrukturierte Quellen auszuwerten – beispielsweise Kundenkommentare, Fotos, Videos, Gesprächsmitschnitte aus dem Call-Center oder Social-Media-Einträge.
Neue Datenstrukturen
Die Möglichkeit, erstmals auch Daten in unterschiedlichen, vorab nicht bekannten Strukturen für Analysen nutzbar zu machen, macht das Thema Big Data für Unternehmen so interessant, weil sie aus der Datenflut echtes Wissen generieren können. „Spannend wird es, wenn Sie nach vorne gucken können“, sagt Thomas Keil, Marketing Manager beim Softwarehersteller SAS in Heidelberg. Also weg von der Frage: Was ist passiert? Sondern hin zu der Frage: „Was passiert als Nächstes? Und was wäre das Beste, was passieren könnte?“ Der Spezialist für BI-Lösungen legt großen Wert auf eine übersichtliche visuelle Aufbereitung der Analysen und Prognosen, damit Anwender in den Fachabteilungen die Ergebnisse interpretieren können. Um sekundenschnell Trends oder Balkendiagramme zu erzeugen, setzt SAS auf In-Memory-Datenbank-Technologie.
Auch im deutschen Handel gibt es erste erfolgreiche Big-Data-Projekte, zum Beispiel bei Otto. Der Internet- und Versandhändler bezeichnet sich selbst als „Data driven Company“ mit langjähriger Erfahrung im Auswerten großer Datenmengen. Um die Sortimentsplanung weiter zu optimieren, hat das Hamburger Unternehmen eine Prognosesoftware eingeführt, die von ehemaligen Wissenschaftlern des europäischen Teilchenforschungszentrums Cern entwickelt wurde. Täglich fließen bis zu 100 Mio. Datensätze in das System. Die Prognosen werden anhand einer Vielzahl von Faktoren berechnet, darunter zum Beispiel die Bewerbung des Artikels in verschiedenen Medien oder bestimmte Artikeleigenschaften. Nach eigenen Angaben gelingt es Otto, Restbestände am Saisonende deutlich zu reduzieren und zugleich die Lieferbereitschaft für die Kunden zu erhöhen, was zu einer Ergebnisverbesserung im zweistelligen Millionenbereich beiträgt.
In einem aktuellen Big-Data-Projekt mit demselben IT-Partner erforscht Otto darüber hinaus, wie sich die Retourenquoten senken lassen: Die Analyse von Massendaten aus unterschiedlichen Quellen hat einerseits typische Retourentreiber wie zu lange Lieferzeiten, ungenaue Produktbeschreibungen oder irreführende Bilder eindeutig verifiziert. Gleichzeitig versetzt die Software das Unternehmen in die Lage, den Einfluss denkbarer Gegenmaßnahmen auf die Retourenquoten zu prognostizieren. So lässt sich beispielsweise berechnen, ob zusätzliche Investitionen in kürzere Lieferzeiten durch sinkende Retouren aufgewogen werden, oder ob sich die Kosten für zusätzliche Abbildungen oder eine virtuelle Kaufberatung rechnen.
Achtung! Diskretion
Zugleich verdeutlicht dieses Projekt aber auch Grenzen von Big-Data-Analysen. Wenn beispielsweise bestimmte Bestellmuster darauf schließen lassen, dass ein Kunde den Großteil der Ware wieder zurückschicken wird, ist es unter Service- und Kundenbindungsaspekten dennoch nicht sinnvoll, ihn deshalb am Bestellen zu hindern oder seine Auswahlmöglichkeiten zu beschränken.
Auch zu persönliche Angebote können die Kunden verärgern. So machte Anfang 2012 der US-Discounter Target Negativschlagzeilen, weil das Unternehmen einem Teenager Werbeangebote speziell für Schwangere geschickt hatte. Bestimmte Veränderungen im Einkaufsverhalten der jungen Frau hatten sie in der Kundendatenbank als werdende Mutter identifiziert. Der Vater der jungen Frau beschwerte sich vehement bei einem Filialleiter in Minneapolis, nur um kurz darauf im Gespräch mit seiner minderjährigen Tochter geschockt festzustellen, dass diese tatsächlich ein Baby erwartete.
Gerade in Deutschland ist Datenschutz ein sensibles Thema. Das zeigen nicht nur die leidenschaftlichen Debatten über die NSA-Thematik. Mehrere Big-Data-Projekte sind hierzulande bereits am Protest von Datenschützern gescheitert. So wollte beispielsweise das Potsdamer Hasso Plattner Institut gemeinsam mit der Schufa Mitte 2012 untersuchen, ob sich aus den öffentlich einsehbaren Facebook-Kontakten eines Kunden Rückschlüsse auf dessen Kreditwürdigkeit ziehen lassen. Und der spanische Telefonica-Konzern darf in Deutschland Auswertungen aus den Bewegungsdaten seiner O2-Mobilfunkkunden bis auf Weiteres nicht zu Marketingzwecken verkaufen.
Bemerkenswert: Trotz der öffentlichen Diskussion stuft nur jedes vierte der vom BARC befragte Unternehmen den Datenschutz als Hindernis für Big-Data-Strategien ein. Die Mehrzahl der Unternehmen beklagt stattdessen fehlendes technisches und fachliches Know-how. Jürgen Boiselle vom Datenexperten Teradata formuliert es so: „Die neuen Technologien erfordern Wissen, das in dieser Form bisher nicht gefordert und daher auch nicht ausgebildet wurde.“ Bis Big-Data-Experten in größerer Zahl aus den Hochschulen kommen, können noch viele Jahre vergehen. Unternehmen, denen es gelingt, die Qualifikationen der vorhandenen Mitarbeiter auszubauen und durch passende Software zu unterstützen, verschaffen sich einen Wettbewerbsvorsprung.
Grafiken (2): Bitkom
Big Data: Interessante und weiterführende Links
- Leitfaden mit Fallbeispielen zu Big Data des Branchenverbandes Bitkom www.bitkom.org/de/publikationen/38337_73446.aspx
- Link zur BARC-Studie „Big Data Survey“
www.barc.de/big-data - Demo des SAS Big Data Tools Visual Analytics
www.sas.de/va-demo - Fallstudie Big Data bei Otto
http://www.blue-yonder.com/downloads/successstory_otto_d.pdf - IBM-Website zu Big Data (englisch)
http://www.ibmbigdatahub.com - Wie wählen die Deutschen bei Facebook und Twitter? www.fanpagekarma.com/wahl2013 und www.twitterbarometer.de

Die Quantifizierung des Bauchgefühls
Den richtigen Blick in die Zukunft können innovative Prognoseverfahren zwar nach wie vor nicht hundertprozentig garantieren, aber ihre Ergebnisse doch immer stärker absichern. Handelsunternehmen, die solche Verfahren heute bereits anwenden, berichten von Prognoseverbesserungen um 30 bis 40 Prozent.
Welche regionalen Angebote sind die richtigen?
Verbraucher legen zunehmend Wert auf die Regionalität von Produkten. Geomarketing ist eine Teildisziplin des Marketings, die durch den Trend hin zu mehr Regionalität im Einzelhandel verstärkt in den Fokus rückt. Es gibt spezielle Dienstleister, die aus Unternehmensdaten und soziodemografischen Daten Geomarketing-Analysen erstellen.